|
首页
>
资讯
>
丹麦药监局起草 GxP 人工智能和机器学习算法标准
出自识林
丹麦药监局起草 GxP 人工智能和机器学习算法标准
2021-03-16
丹麦药品管理局最近发布了一份问题清单公开征求意见,以定义适用于各种关键 GxP 监管领域(例如,生产、分销和临床试验)的人工智能(AI)/机器学习(ML)算法的标准。丹麦药监局表示,其拟议的标准不是“完整清单”,应被视为“成熟草案”的提案,邀请利益相关者在 4 月 30 日之前对此主题提供反馈。
标准适用于实现关键 GxP 相关功能并且可以使用监督学习进行训练的静态 AI/ML 算法。丹麦药监局的提案列出了与使用此类算法相关的标准和问题,主要分为三大方面:数据集、偏差和方差、混淆矩阵和度量指标以及对结果的解释。
另外,丹麦药监局解释指出,提出该拟议提案的原因是“目前的立法中没有任何直接解决 AI/ML 算法使用问题的法律。”虽然该提案是丹麦药监局的内部提议,但是在欧洲和国际背景下起草的,具有普遍参考意义。
关键 GxP AI/ML 应用程序的问题
基于静态 AI/ML 算法和监督学习
pdf
数据集
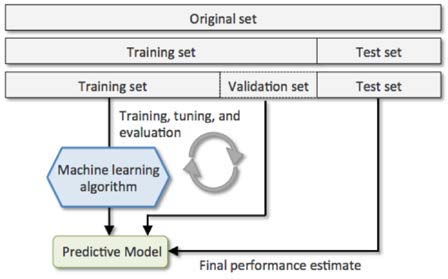
1. 算法的训练、验证(优化)和测试过程是什么?谁参与了不同阶段?与计划有哪些偏差(如果有)?
2. 用于训练、验证和测试算法的数据集有多大?如何识别(命名)每个组中的每个单独的数据元素,以及将数据集存储在何处?
3. 有什么证据表明,用于测试算法的数据集中的部分之前没有被用来训练或验证(优化)同一算法,或源自同一主题?
4. 用于测试算法的数据点何时与完整的数据点池分开?使用了哪些选择标准?
5. 测试数据应遵循哪种数据清洗、标准化、均质化、排除标准、数据合成或类似方法?为什么?
6. 如何确保测试数据集能够代表应用程序预期范围内的真实数据并包含足够的挑战性数据(例如,西伯利亚雪橇犬还是狼)?
7. 训练数据集中的哪些特征对算法的输出影响最大,如何影响选择?与测试数据集如何对应?
8. 如何确保测试数据集涵盖由于人员、过程和设备的差异而在实际数据中可能出现的任何技术差异(例如,格式)?
9. 如何对用于训练、验证和(特别是)测试算法的数据的正确分类进行确认,并由诸如第二人或实验室测试确认分类?
10. 测试数据已有多少年了,并且仍然相关吗?算法的 F1 分数是否可能会由于输入数据随时间的变化而变差(例如,由于 COVID-19 封锁期间健身中心关闭而导致健康数据发生变化),如果是,那么数据集的重新训练和校准计划是什么?
偏差和方差
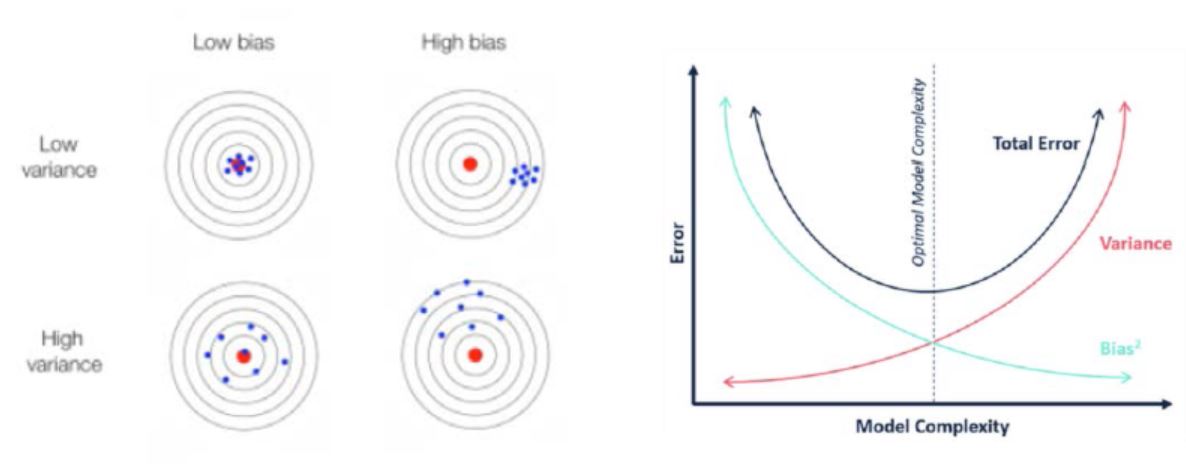
11. 如何对算法进行优化以处理偏差(Bias)和方差(Variance)(偏差–方差权衡)?在测试中看到的优化结果是什么?偏差–方差权衡图的外观如何?
a. 偏差是来自学习算法错误假设的错误。高偏差可能导致算法错过特征与目标输出之间的相关关系(欠拟合)。
b. 方差是对训练集中小波动的灵敏度误差。高方差可能导致算法对训练数据中的随机噪声进行建模,而不是对预期的输出进行建模(过拟合)。
12. 如何在连续的训练、验证和测试周期中监控系统性能?例如,F1分数从70-80-90%可能表示由于过拟合导致算法过于自信。
混淆矩阵和度量指标
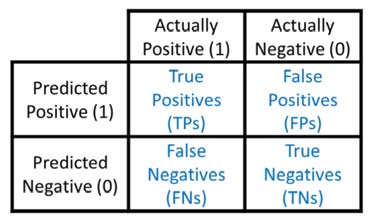
13. 混淆矩阵(TP/FP/FN/TN)和以下指标中的值是多少?
a. 灵敏度 [TP/(TP+FN)] 是总真阳性中正确识别为阳性的项目数。灵敏度也被称为召回率(Recall)、命中率(Hit Rate)或真阳性率(TPR)。
b. 特异度 [TP/(TP+FP)] 是总真阴性中正确识别为阴性的项目数。特异度也被称为选择性(Selectivity)或真阴性率(TNR)。
c. 精确度 [TP/(TP+FP)] 是总识别为阳性的项目数中正确识别为阳性的项目数。准确度也被称为阳性预测值(PPV)。
d. 假阳性率 [FP/(TN+FP)] 是总真阳性中被误识别为阳性的项目数。例如,一名男子被宣称怀孕。也称为 I 类错误。
e. 假阴性率 [FN/(TP+FN)] 是总真阳性中被误识别为阴性的项目数。例如,一名孕妇被宣称未怀孕。也称为 II 类错误。
f. 准确率 [(TP+TN)/(N+P)] 是正确分类的项目占总数的百分比。不应将其用于不平衡的类别集,因为一个类别的准确性会压倒另一类别。
g. F1分数[2*(精确度*灵敏度)/(精确度 + 灵敏度)] 是精确度和灵敏度的调和平均数。F1 评分优于准确率的优点是,对于不均匀的类别,可以提供更好的度量标准来计算模型性能。
结果解释
14. 对于应用程序的预期范围,混淆矩阵中的哪个象限和哪个指标更重要,并且如果看到较低的分数,为什么这些部分不那么重要?
15. 如何根据测试数据和测试结果(包括混淆矩阵和度量指标)来定义和限制应用程序的预期范围?
16. 如何定义最终结果的阈值,例如,“ 50.01%它是一只狗”的结果是否解释为结果“它是一只狗”?如果需要,结果何时需要人的参与?
作者:识林-蓝杉
识林®版权所有,未经许可不得转载。如需使用请联系 admin@shilinx.com 。
|