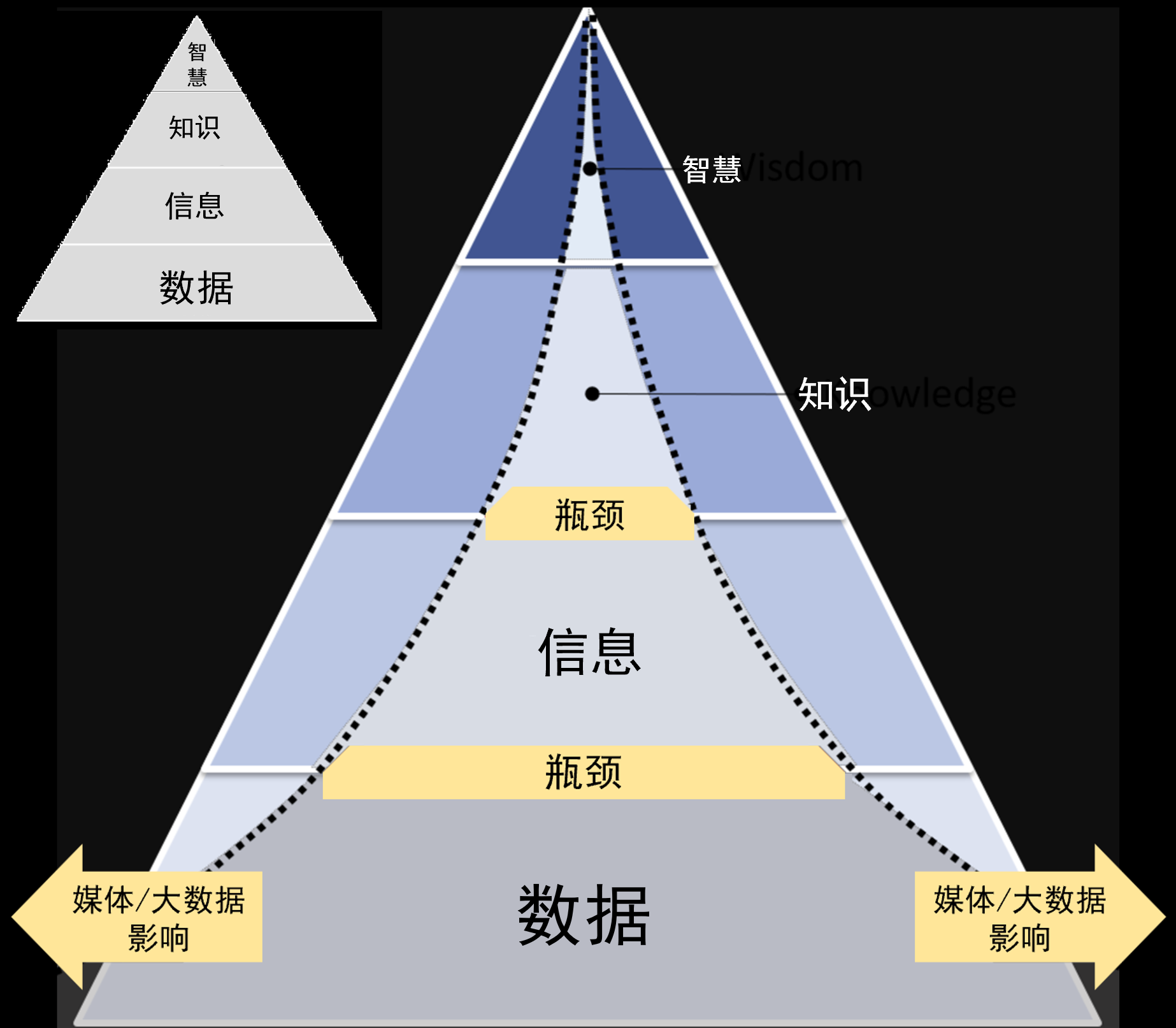
最近看到来自美国纽约的Alphacution Research Conservatory公司画的“数据-信息-知识-智慧”金字塔(如下主图所示)显示从数据到智慧的这条路,不仅是越走越窄,而且收窄的越来越快。如果说三角形的金字塔,显示的是从真实数据到智慧的“蒸馏”,中间那个顶部细尖的弯曲三角形也许更形象地显示了未来从真实数据和合成数据的混集中“蒸馏”出智慧的路会变得越发难走。这是因为,合成数据产生的速度会越来越高于真实数据产生的速度。也就是大模型的训练集中,会有越来越大的比例来自合成数据。这预示着大模型的功效会逐渐进入收益递减的成熟期。