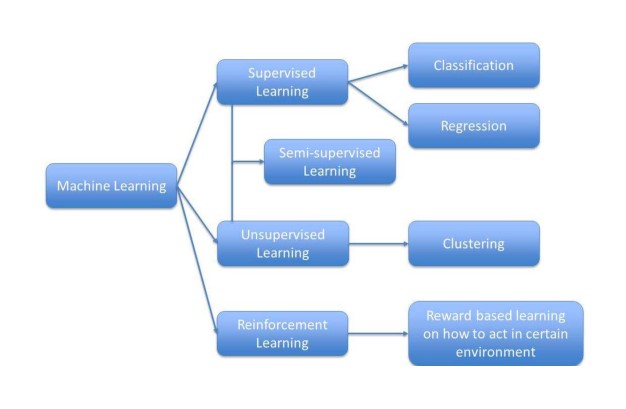
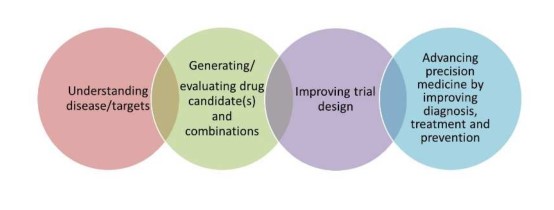
作者表示,近年来,FDA器械和放射健康中心(CDRH)已经收到了一些基于ML的医疗器械独立软件(software as a medical device,SaMD)意见书,其中许多是以影像数据为基础的诊断软件。随着这些算法在促进药物研发和指导患者用药方面的探索应用不断增多,FDA其他下属机构,如 CDER 和 OCE 已经投入资金用于学习最前沿的ML算法。从目前来看,一些算法仍然需要长时间的调整和适应,以进一步提高其性能 (例如,准确性)。因此,为促进申办人对SaMD的进一步改进,确保它在应用中的安全性和有效性,FDA正在开发一个监管框架。虽然该框架是主要是为SaMD设计的,但也为将来ML在药物研发方面的应用审批提供了依据。
参考资料
[1] Qi Liu et al. Application of Machine Learning in Drug evelopment and Regulation: Current Status and Future Potential. Clinical Pharmacology & Therapeutics. https://doi.org/10.1002/cpt.1771
[2] Luo YN et al. A Network Integration Approach for Drug-Target Interaction Prediction and Computational Drug Repositioning from Heterogeneous Information. 2017. Nature Communications. 10.1038/s41467-017-00680-8.